a heatmap makeover

I often describe heatmaps as a good means for getting an initial view of your data. They can help you start to explore and understand where there might be something interesting to highlight or dig into. But once you’ve identified the noteworthy aspects of your data, should you use heatmaps to communicate them?
As often is the case, it depends.
If you are communicating to an audience who likes to see data in tables—applying heatmap formatting can provide a visual sense of the numbers without fully changing the approach (or having it feel like you’ve taken detail away). If you know your stakeholders will want to look up specific numbers (particularly in the case where different stakeholders will care about different numbers) and then understand them in the context of the broader landscape, a heatmap may also work in this scenario.
That said, we can often make things easier by fully visualizing data in a graph. Let’s consider the heatmap at the onset of this post. First, I’ll take some steps to improve it. After that, I’ll explore a couple ways to graph the data. As I walk you through my process, I encourage you to compare the different views and decide which you like best. Why is that?
To start, I’ll change the colors. Red-green color scales can be problematic for colorblind audience members (the most common type of coloblindness is red-green colorblind, where both red and green end up looking brownish, which can be particularly difficult if they are similar in intensity). I played with a few color combinations, using conditional formatting in Excel. The following shows my iterations.

I started with a 3-color scale, setting bright blue for the lowest value, white for the 50th percentile, and orange for the highest value (top left). Because of their concentration (both in intensity and relative proximity), the blues stood out more than I wanted, and the white cells also competed for attention. To adjust, next, I tried lightening the blue and moving from white to grey for the 50th percentile (top right)—this made everything look muddled. For my third combination, I lightened the blue and reverted to white for the 50th percentile (bottom left). I felt good about this one but also tried one more version, a 2-color scale with orange for the highest value and white for the lowest (bottom right). This final view puts clear attention on the sites with higher error rates—something likely worth noting.
Which of the above variations do you prefer? Are there other changes you would make to this heatmap?
In terms of other changes I’d like to make: I would advocate reducing the precision. Not only does this many decimal places make the numbers difficult to talk about (“Site C has the highest monthly error rate over the past six months, averaging oh point three six four percent per month”) but it’s also not likely that this is true precision. If these are manufacturing sites, we’re not likely evaluating every single unit made for errors, but rather some sample, which means there’s natural error to our numbers. Due to both of these reasons, I’ll round to the nearest hundredth (if we go further than that, we’ll lose the ability to differentiate between many of the numbers given their magnitude).
Also, if there’s not a compelling reason to keep the sites ordered in the manner they are currently, I’d be inclined to order them according to the error rates. To direct attention to higher error rates first, I’d start with those and order by decreasing error rates as we move from left to right across the heatmap. The following two views (colored the same as the final two iterations above, respectively) reflect these changes. I also included a screenshot of the settings I used I achieved each via conditional formatting in Excel (to access this screen, go to the Format dropdown and select Conditional Formatting, then click + to set a rule).


We could arguably make some additional changes to the heatmap (for example simplifying the date format or eliminating or lightening borders). But rather than make more modifications to this view, let’s look at some ways to more fully visualize this data.
When I encounter data over time, the first graph type that comes to my mind is a line graph. However, if we graph the error rates for all of these sites, we end up with a tangled mess:

Depending on how we are presenting the data and what we want to highlight, however, it’s possible that we can make this tangled mess work. For example, let’s imagine we are presenting live and want to focus on a single site at a time. I can do this in the line graph and might also pair it with a horizontal bar chart to focus specifically on how error rates across the sites compare as of our most recent monthly data point. Let’s focus first on Site C:

I could cycle through the other lines and bars one at a time. In a written report, this approach of repeating the same graphs with different segments highlighted can also sometimes make sense. For example, I could have a section in my report for each site using a setup like this, perhaps also adding commentary in each section to explain the relevant context.

As another option—and this is one that often works well when faced with a spaghetti line graph like the one above—I might try visualizing the data in a panel chart. Whereas in the last example, I was cycling through the same graph with different points of emphasis, the panel chart shows the same graph for each segment all together in the same view. In the following, the primary comparison that’s easy to make is how error rate for a given site has changed over time. I can also see each site in the context of the rest. This could be an alternate view to meet the needs of a mixed audience, who each wants to concentrate first and foremost on their section of interest, but also understand how it fits into the broader context.
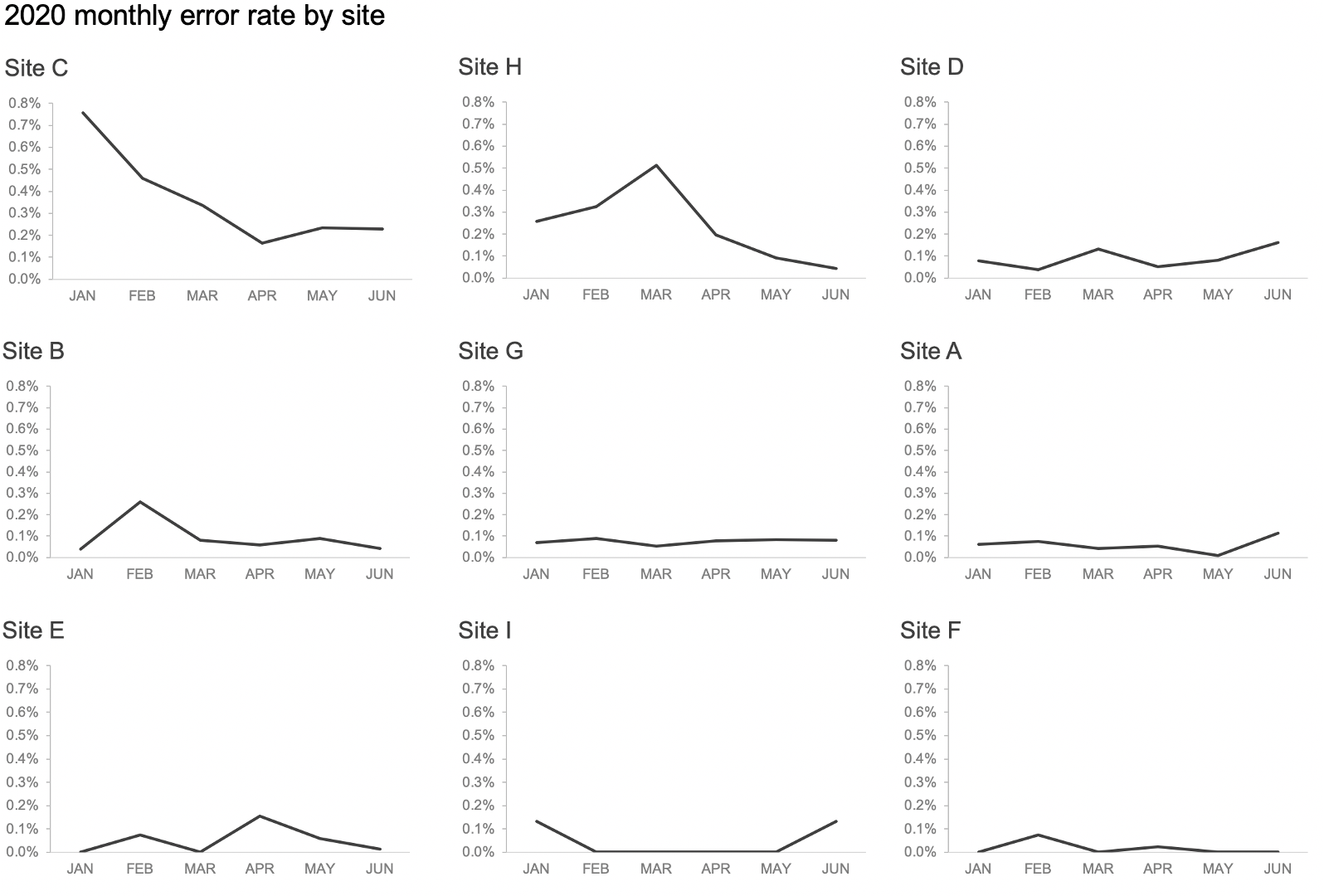
The preceding view (which is nine separate graphs arranged to look like a single visual) could work great to analyze trends across the different sites as we continue to explore our data. Once we’ve done that and have some specific points we want to communicate, I could add framing and sparing emphasis to direct my audience to the important parts. For example, in the following, I categorized each site based on the latest month-to-month change (down = SUCCESS; flat = STATUS QUO; up = WATCH). I also highlighted and annotated some possible areas of interest.

Did you decide which view you like best? I’m partial to this final one, but different scenarios and constraints might call for a different approach.
To practice on your own with this example (you could even try emulating one of the approaches I’ve shared here in your tool of choice), check out the exercise take it beyond the table.
You can also download my Excel file with all of the graphs from this post.